Explaining Software: Interview Questions

- Pretend I'm not a tech person. Can you explain REST in simple terms?
Everyone can be a tech person and I hope that my explanation covers the concept and intentions behind REST (REpresentational State Transfer).
Executive Summary:
REST is an informal software specification/guideline/principle to creating patterned stateless access to web resources. Key benefits of using a stateless format to access and transition web resources is performance, reliability, scalability, patterned visibility, and other important benefits. In general the use of REST to create web accessible resources will keep your architecture available and accessible with a lower software cost on the modern web.
Detailed Summary:
REST is an idea that the states of web resources can be represented in a stateless manner through the composition of the request, payload, naming, and etc. A web resource in this case can be any accessible item on the World Wide Web (abbreviating to web from now on)
This is a software idea that does not have a formal specification in the vein of an IEEE specification like IEEE 1394 for example. In general the idea is to use the HTTP (HyperText Transfer Protocol) verbs like {GET, POST, PUT, DELETE} (most common ones), requesting resources Uniform Resource Identifier (uri) also url parameters {like id=X}, HTTP headers for expectations/control like {User-Agent, Accept, Accept-Encoding, Cache-Control}, and HTTP status codes for further instructions such as the common 200 OK, 301 Redirect, etc
When implemented it provides a user of the system from a general browsing user to a programmatic consumer of Application Programming Interface (API) the ability understand the reasoning and follow common patterns to explore and reach resources without surprises in behavior or the need to keep some form of session state (in memory, databases, etc) active to continue navigating and using the interface.
Example request with explanation:
Given that you would like to access an article from your favorite website in this case it is my article on sql locking https://siliconheaven.info/sql-locking-walkthrough
In this case you will use a HTTP GET (GET requests in REST should be idempotent and as such are great for caching)
Breaking this down it is as this HTTP request
- Scheme: https (we are stating to use the secured certificate public/private key exchange to encrypt our session)
- URI Authority: siliconheaven.info (base domain to be addressable by world wide Domain Name System (DNS) in essence a lookup table for translating the text to an internet protocol address
- Path: sql-locking-walkthrough (navigate to this path on the applicable web location the article target resource)
- Headers: Accept: */* (all HTTP media content types) in essence we are asking the response to send us back the media in its choice of content type
Now the RESTful response will represent a resource state to render and with the response media content type indicate how to specify and process subsequent requests from the content.
In this case the response will send back the contents along with headers so that the handler application, etc can use the content through the content type i.e. text/html for browsers, application/json for most modern web APIs.
Following this pattern and some human intuition we can posit the guess that https://siliconheaven.info/resumewill take you to a web resource that contains my resume. This is true, but in this case the immediate response makes use of the HTTP status code 301 to indicate that the above REST resource location is going to redirect to another location in this case https://siliconheaven.net/resumedocs/
Further refinement can be done along the use of POST(create a complete new resource from POST content), PUT (modify a web resource, by taking existing content with modification) PATCH is the partial modification of the resource, DELETE the removal of the target resource. The general guidelines is to make these requests idempotent as possible and without side effects or returning to the original point of REST that the state transition of the request initiated under REST will describe the state transition from the current state you are at now to the future state without having additional implied state transitions and handling out of control and access of the requester.
- Do your best to describe the process from the time you type in a website's URL to it finishing loading on your screen.
This will be my interpretation of this from a software standpoint. There are many abstractions and assumptions that will be covered by a larger overlying software abstraction.
Assumption: You are using a modern web oriented browser such as Chrome, Firefox, Brave, etc
When you type in url into the browser at the input text area like so

- The browser takes the text and then breaks out the base URI first in this case siliconheaven.info
- It takes this URI and from your current network interface sends a Domain Name Service DNS. This is to ask your network interface where it will need to send the information of this request. As an abstraction think of this as lookup table where the name
siliconheaven.infois an ip address = IPV4 (142.93.24.144), IPV6 (2600:1700:564:e380::1). This can be verified through the use of the nslookup tool like sonslookup siliconheaven.info. It is illuminating to use this tool at times when your request may be proxied without your knowledge therefore sending your request to a location that is not expected. - Now that your browser knows the IP address of where to send a HTTP request it will first open a TCP/IP socket to communicate with the web server and since the scheme here is specifying https it will use port 443 as the target communication port, your local machine port will be a random port number most likely between 1023 and 65535. As HTTP was intended as a human readable protocol built on top of the lower level of socket communication between known machine address (there is an entire level of communication fallback formats, handshakes, and TCP/IP protocol communication here that I am abstracting away as it works and we use it. I am aware of it and know the details or where to look them up, but suffice to say TCP/IP was chosen for the socket communication because it is reliable and messages are ordered along with an ability to vary packet size, etc. I digress)
Some details are here if you want to see in detail, use command netstat -an | find “443”

- Now that you are connected a HTTP GET request is initiated as that is default request type for a modern browser along with some other assumption like so:
- Note that the use of
httpsscheme means that public/private key exchange must be done for this session along the socket443to establish that the content returned from this server is certified through a trusted certificate service as valid (in this case it is letsencrypt.org). This is to give some protection from eavesdropping and direct monitoring of the content the client and server are intended to have access and allowed to view the contents of the bytes sent between the various intermediate 3rd parties who should be unable to view the direct contents only the encrypted bytes.
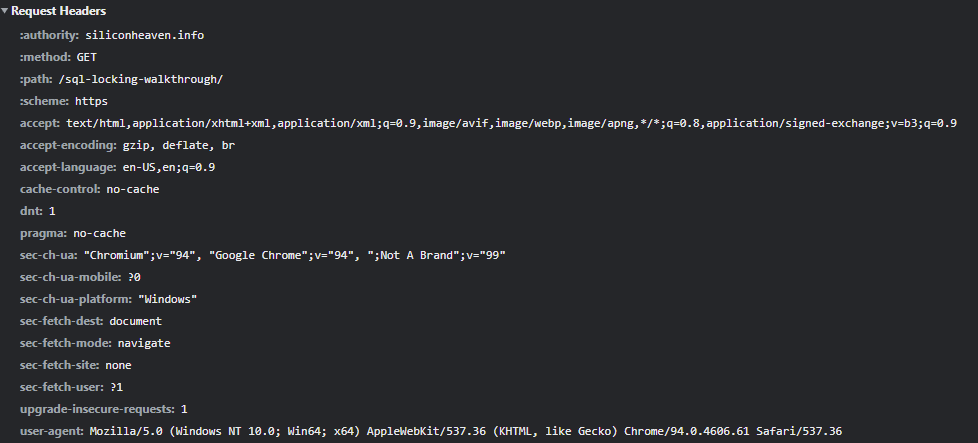
- Now this request can get directed through various networks and or content delivery network networks (CDN), but in this case I don’t have any of that setup so it will go directly to this machine specified and the server will then interpret this request and send the response.
- Server interpretation of the request is highly variable and dependent on what is being accessed and the underlying technologies, but I will describe my setup here in that the request is handled first by nginx proxy which then forwards the request over to a nodejs express server running in pm2 which then interprets the request and loads the resources from static content to database parameterized content. I am abstracting this away as simply HTTP content will be returned that corresponds to the requested entity along with instructions on handling the content type and it’s format.
- This HTTP response is then relayed back to the client browser and looks something like this as headers which inform the browser how to handle the HyperText Markup Language (HTML) content
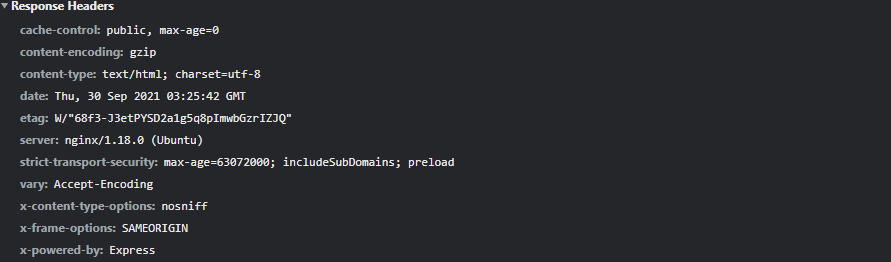
- The details of the content once the bytes have been decoded and organized will look like a document that the browser can then begin rendering according to the HTML standard implemented by the browser. I am glossing over a lot here that is important, but entire libraries of reading material are created to handle this I would suggest this for learning more here
<!DOCTYPE html>
<html lang="en">
<head>
<title>Sql Locking Analysis</title>
<meta charset="utf-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
...
<script type="application/ld+json">
{
"@context": "https://schema.org",
...
<script>
$(document).ready(function () {
// Mobile Menu Trigger
$('.gh-burger').click(function () {- As you see above the HTML content is a document which is then interpreted according to the browsers and operating system render components which can be different for each element as a HTML select is rendered differently in different browsers and operating systems
- At this point above document as you can see has further instructions as well on linked content, scripts, images, cascading style sheets, etc and will repeat the above request/response/render until all accessible content from the above HTML original document is available. This process can take quite awhile and open numerous connections with modern websites (JavaScript bloat mostly to blame here)
- If you were to start a website project today, what are the tools and libraries you would use (e.g. front-end UI, data access, etc.). Please also describe why you've selected each and what you would use each for
First I would like to raise the point that the application framework libraries code should be designed to exchange messages in an agreed format and serialization say JSON or message bus messages and then it doesn’t matter what technology you use or if it is is serverless, containerized, etc. What I mean is that python code can communicate with .NET Core to JavaScript, Rust. In fact I have done this before and when the serialization format is explicitly specified you can do true polyglot development.
Datastore: Postgres(rock solid, open source, documentation and vibrant dedicated community), AWS Aurora if you are ok with being an Amazon customer for all your technology infrastructure. Aurora gives automated failover and read replicas as strong points to use
Data Access: ServiceStack OrmLite or Dapper both are parameterized, performant, and minimal with ServiceStack OrmLite adding in all the niceties that you need to mix/match Dapper with other extension libraries to it. I know that ServiceStack may seem out of the ordinary, but I know it inside out and have worked with the founders, given presentations on it, and agree with the message based Data Transfer Object (DTO) first approach
Application Framework: ServiceStack it is as they say a batteries included get to building your projects instead of doing setup and handling that .NET Web API (.NET Core on Linux only) uses (although I would not be opposed to MVC, it is that the application framework has grown too large to satisfy a huge variety of conditions. This is where the ServiceStack opinionated development saves you a lot of trouble)
Application Caching: Redis (it’s the best). It is fast, reliable, tested, and predictable. With an impressive command line interface if needed
Front End: React it’s has a large, vibrant community with documentation that is guaranteed to survive. The use of state management is up to debate and I would hold off on using anything until it is necessary and my experience with Redux is that the formalization and learning is quite a bit, maybe Hooks or useContext
Logging: SEQ, structured logging is a must for any modern web application and SEQ is powerful, feature rich, and surfaces meaningful data with alerts, graphs, etc
Job System: Hangfire or can fallback to QuartzNet, you are going to need some way to schedule and run long running jobs especially if doing serverless development and HangFire gives you a nice UI and I have worked with both and that UI is quite powerful and useful at times
API Docs: Swagger, when creating services you should have a way to access and document the endpoints for use
API helpers: cURL + Postman you are going to have to debug your services at some time and you should make them work with standard scriptable tools like this
Development: Visual Studio, Visual Studio Code, JetBrains Rider, I have used all of them and well I think Rider is better, but Visual Studio does have the more powerful debugger so it still serves a need.
Messaging: Azure Service Bus, Azure Message Queue, AWS SQS, AWS SNS message passing is important to any microservice architecture and going to have to pick a message provider so use any of the above. Don’t go with a RabbitMQ as you have to run it and well message queuing and bus handling should be done by a big service provider
Dependency Injection: So many to choose from I guess Autofac
Deployment format
Choice 1: Serverless, this is the abstraction that if you can manage resource allocation and timing will simplify your deployments and gives you a microservice architecture out of the box as you have to work hard to tie components together into a monolith under this format
Choice 2:
Containers: Docker, it is a well adopted pattern and considerably less work than others I have seen like Kubernetes, but now if I had the choice I would skip this completely and go straight to serverless. In this case you will need a private registry so Amazon ECR, Azure Container Registry, Docker registry etc.
In general available tools and languages to keep around for experimentation Dart, SvelteJS, Vue, Python, Rust, Pandas, TypeScript, etc. I strongly believe in experimentation and trying new things as new techniques and ideas have to come from somewhere and these breakthroughs in software should not be limited big companies. You do need to pick your targets as building a new database in Rust may not be appropriate, but maybe?
So many things to consider, but this is a rough start.
- Explain the difference between var and object in C#.
var is an implicit type, which means that it can only be used in situations where the type can be inferred say within a function method where the return type is defined for example.
private int Count()
{
var z = 0;
return z;
}This is not legal as the type can not be inferred
private var Zebras { get; set; }
object is the base type for all non primitive types so in essence everything can be downcasted to an object and as it is not an implicit type it can be use without having to do inference. It is an explicit type
Thus this is legal syntax
private class Giraffe
{
public string MyName { get; private set; }
public Giraffe(string name)
{
MyName = name;
}
}
private List<object> Animals { get; set; }
public void AddAnimal()
{
Animals.Add(new Giraffe("Johnny"));
}You can add primitives like int to this as well but have to box them like so (object)
Animals.Add((object) 1); // I would not recommend doing this ever
- What is database normalization?
Database normalization is the process of structuring data in table so that data redundancy is removed and the relationships between tables are strongly tied and validated. There are several forms of normalization and it can be applied in normal forms raising the integrity and relationships within the database.
In general use primary keys on tables, then foreign keys for relationships of parent→ child tables.
I do this all the time and can give you some formal examples upon request if you would like. Taking denormalized data (excel files are often guilty of this) and structuring this until it is in reasonable higher normal form.
- In JavaScript, what are the differences between variables created using let, var or const?
var is the old school JavaScript way to declare variables. It can hoist it’s value in the same calling block can sit outside of its function scope, can be globally declared, is fine to declare multiple times, etc. In general it can get you into a lot of trouble in large code blocks because so many unexpected situations can occur
This is ok and confusing
var a = 1;
var a = 2;let is a way to declare variables that you used to say var that is now properly scoped to the enclosing function method, class, and does not allow for hoisting, redeclaration, etc. You should use let whenever possible to save yourself and others from all the weirdness of JavaScript
This is not ok, thanks let
let a = 1;
let a = 2;const is a way to tell JavaScript that this variable can no longer change it’s reference. This means that you have to declare a const with a value and you can change value it represents, but you cannot change the assignment so protects you from turning your const into a let or var variable and holds your value. It’s a little subtle, but it protects you for example
This is ok with a const
const number = { a: 5};
number.a = 6;This is not ok
const number = 5;
number = 6;