SQL Techniques - Third Normal Form (3NF)

Relational databases are built on the concept of entities and their relationships to each other. From time to time the relationship between tables is a Table1 < N – N> Table2 or table 1 data relates to table2 data in a non unique form. In this case a bridging table is a good solution to create the appropriate dependency relationship. This is known as Third Normal Form (3NF). The following is an example situation along with the structures and queries to find the correct corresponding data.
Problem
- You have a
Documentstable that contains some text - You have a
Keywordstable that contains the indexed and relevant words that may be within the text of a document
Say you have a Documents that contains the sentence. Monday was not my best day. Now you also have Keywords that are for the days of the week, therefore Monday is a record within that table.
How to efficiently process the documents for keyword lookup within the Documents table. In this case we are introducing a new table DocumentKeywords this is the bridging table between the two entities and records are added or deleted from this table when either the Documents, Keywords tables are updated.
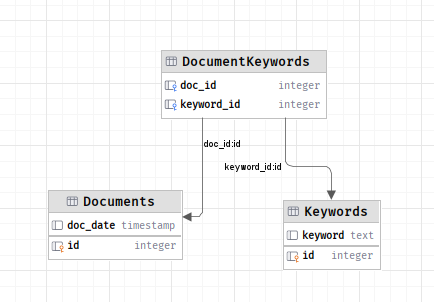
Here is a diagram of the current database layout
Diagram
Setup (Sqlite)
drop table if exists DocumentKeywords;
drop table if exists Keywords;
drop table if exists Documents;
create table Documents (
id INTEGER primary key autoincrement,
doc_date timestamp
);
create table Keywords (
id INTEGER primary key autoincrement,
keyword text
);
create table DocumentKeywords (
doc_id INTEGER,
keyword_id INTEGER,
FOREIGN KEY("doc_id") REFERENCES "Documents"("id") ON DELETE CASCADE,
FOREIGN KEY("keyword_id") REFERENCES "Keywords"("id") ON DELETE CASCADE
);
insert into Documents (doc_date)
values ('2020-01-01'),
('2020-01-02'),
('2020-01-03');
insert into Keywords (keyword)
values ('Blue'),
('Yellow'),
('Red'),
('Orange');Filling in some relationships only for illustrative purposes
insert into DocumentKeywords(doc_id, keyword_id)
values (2, 1),
(2, 2),
(4, 4),
(3, 1);From the above you see we have 2 documents that share unique keywords. Document 2, 3 both have Yellow and we have 1 document that contains multiple keywords Document 2 contains Yellow, Blue
Query
How do we identify all documents that contain both keywords Yellow, Blue ?
First get all the keyword ids that are within documents for the above keywords
SELECT id
FROM Keywords
where keyword IN ('Blue', 'Yellow')Now we need to make sure these are joined to match all document keywords
select dk.doc_id
from DocumentKeywords dk
inner join
(
SELECT id
FROM Keywords
where keyword IN ('Blue', 'Yellow')
) k
on dk.keyword_id = k.idOk that works, but the problem is that it returns all matches not the ones in both
| doc_id |
|---|
| 2 |
| 2 |
| 3 |
In the above since there are two keywords then we only want the matching document ids that are matched at least 2 times. Therefore do a group by with a having count(*) > 1.
select dk.doc_id
from DocumentKeywords dk
inner join
(
SELECT id
FROM Keywords
where keyword IN ('Blue', 'Yellow')
) k
on dk.keyword_id = k.id
group by dk.doc_id
having count(*) > 1;| doc_id |
|---|
| 2 |
Ok we have the correct result now make it slick with a Common Table Expression (CTE)
WITH mult as (select dk.doc_id
from DocumentKeywords dk
inner join
(SELECT id
FROM Keywords
where keyword IN ('Blue', 'Yellow')) k
on dk.keyword_id = k.id
group by dk.doc_id
having count(*) > 1)
SELECT d.*
FROM Documents d
inner join mult
on d.id = mult.doc_id;| id | doc_date |
|---|---|
| 2 | 2020-01-02 |
