AWS Textract PDF to CSV

PDFs are great for presenting information, but due to their structure and formatting getting structured data out of them is difficult and tedious and they could be considered unstructured data in my opinion.
Say you have a PDF document like this, which is really a long table with a lot of valuable information that you would prefer is in proper structured data format like csv
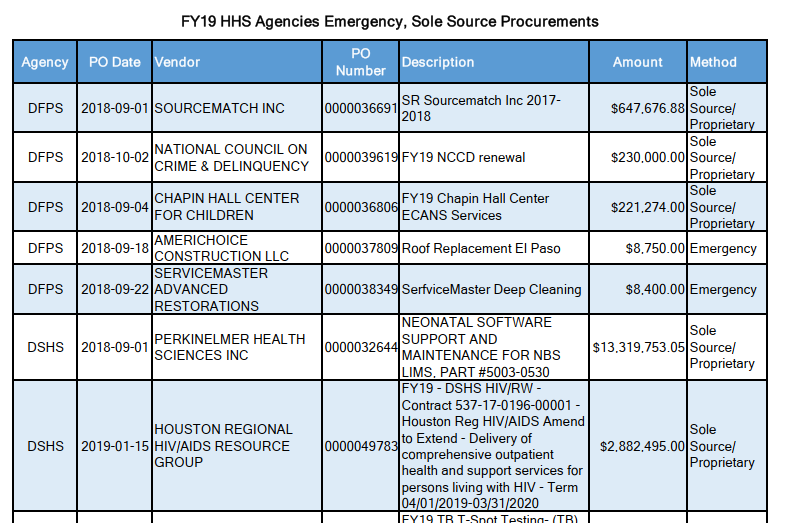
AWS Textract is the main tool I will use here to extract the tabular data

This document is from here
This is what AWS Textract can infer from the Analyze Document demo page
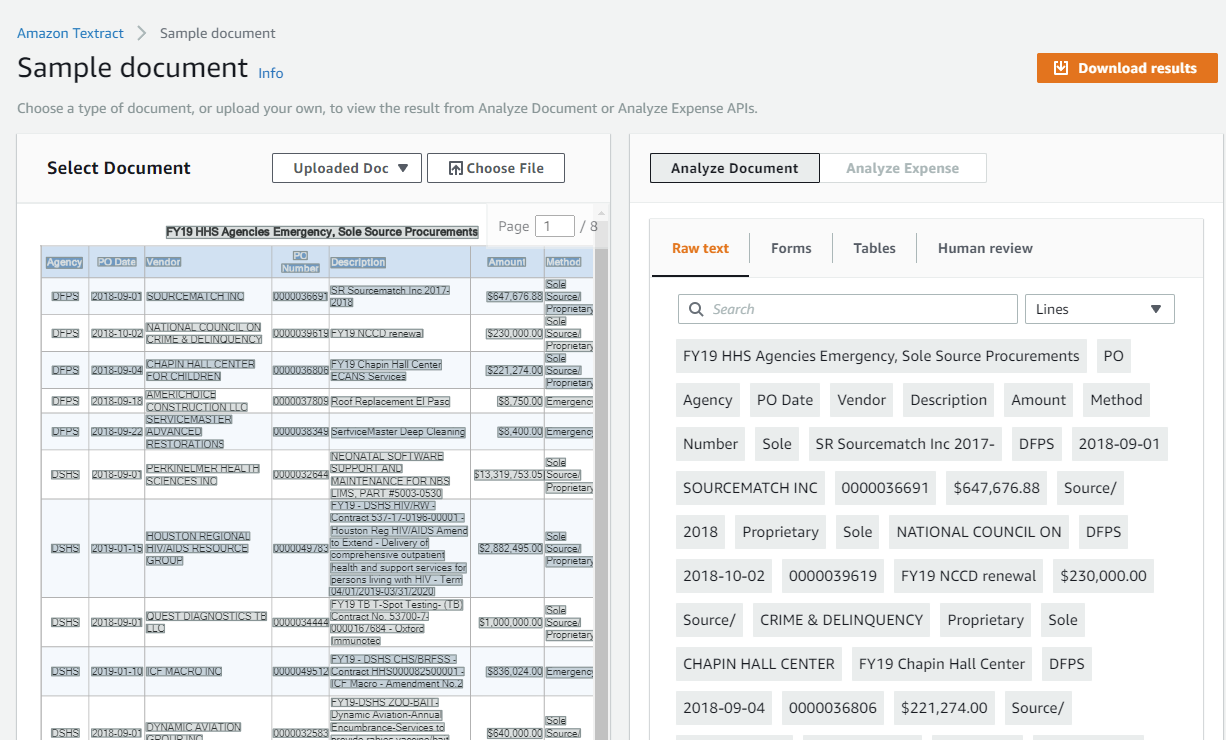
The table extraction part is great
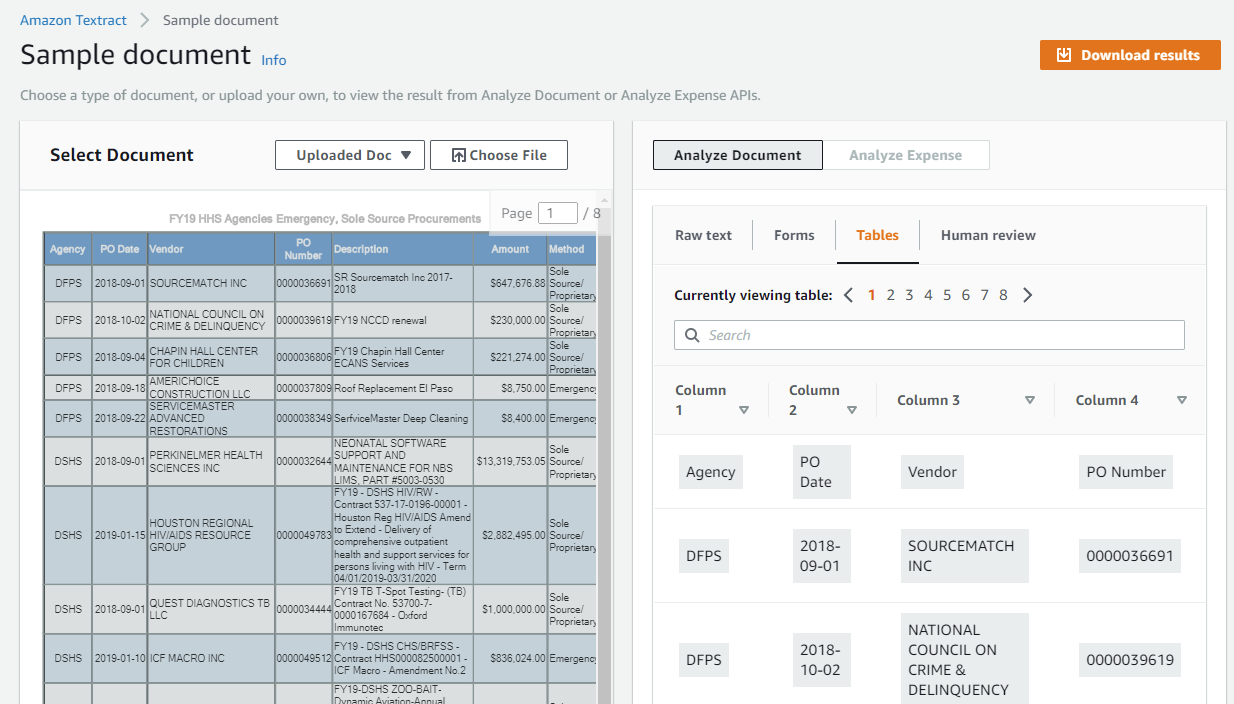
Now this is not the format you will receive back, but a slick sample representation that you can gather from the JSON response document they will supply you (has confidences, types, relationships, etc). I want to get the pages table contents into a consolidated CSV file.
Plan
With the goal of zen programming using straightforward minimal tools let's do the following steps
- Find utility tools that will parse/extract pdfs
- Parse out the pdf contents into pages, read bytes
- Extract the data with AWS Textract
- Put it all back together as a nice CSV file
First use virtual environments. If you don't then after 1 or 2 python projects you will be in a world of pain.
- Install python3 environments
sudo apt install python3-venv -y
- Create a python3 virtual environment
python3 -m venv env
- Activate the environment
source env/bin/activate
Here is my pycharm setup currently
First step we still will need some utility programs available (this is more difficult in Windows, but completely possible)
Install the following utility applications as we will be using pip shims to interact with the tools
pdftoppm
Great utility that will read pdf files and extract each page as image file like so from the command line pdftoppm ${file}.pdf ${file} -png;
You should run the above command against a sample pdf to confirm that your paths are setup and the tool works.
Second step install python library tools for processing, I have output my current imports and came up with the following
boto3==1.19.7
botocore==1.22.7
certifi==2021.10.8
charset-normalizer==2.0.7
et-xmlfile==1.1.0
idna==3.3
jmespath==0.10.0
numpy==1.21.3
opencv-python==4.5.4.58
openpyxl==3.0.9
pandas==1.3.4
pdf2image==1.16.0
Pillow==8.4.0
pytesseract==0.3.8
python-dateutil==2.8.2
pytz==2021.3
requests==2.26.0
s3transfer==0.5.0
six==1.16.0
urllib3==1.26.7
Key libraries above are boto3, numpy, Pillow, pdf2image, opencv, requests Start with installing those and then add the others as needed
Third step - Here is the code I wrote which
- Grabs a pdf document
- Reads the response into a byte stream
- Copies the bytes to a file
- Reads the pdf file contents as byte array
- Creates a
textractAWS boto3 client (using the assumed API credentials on your system which you have setup beforehand) - Converts the pdf bytes into images 1 per page using the poppler tool
pdftoppm - Read the Pillow format image as a byte array
- Sends the byte array content to AWS textract client and to look at for tables
- Extract each tables as a set of numpy dataframes
- Concatenate all the numpy dataframes together
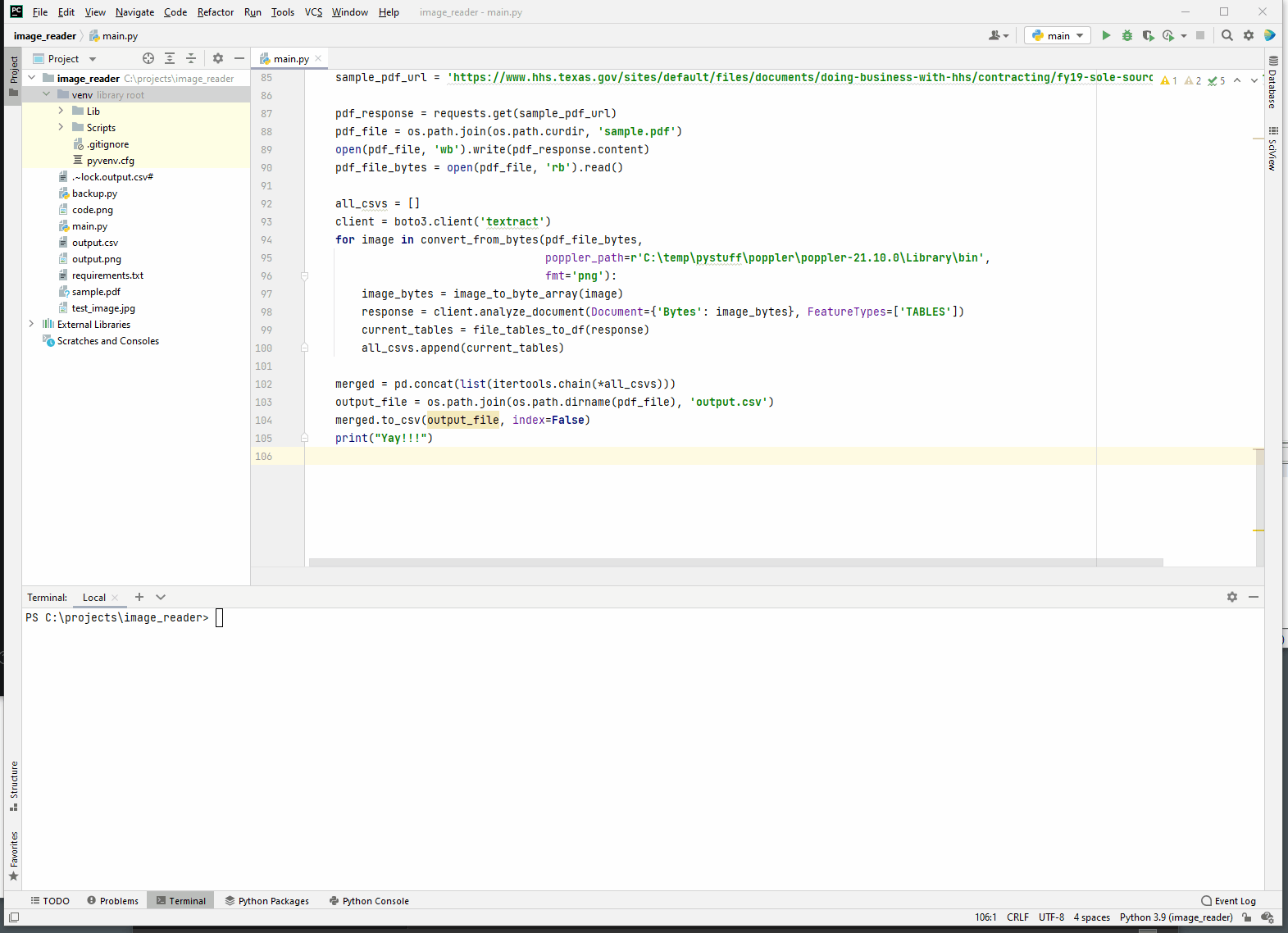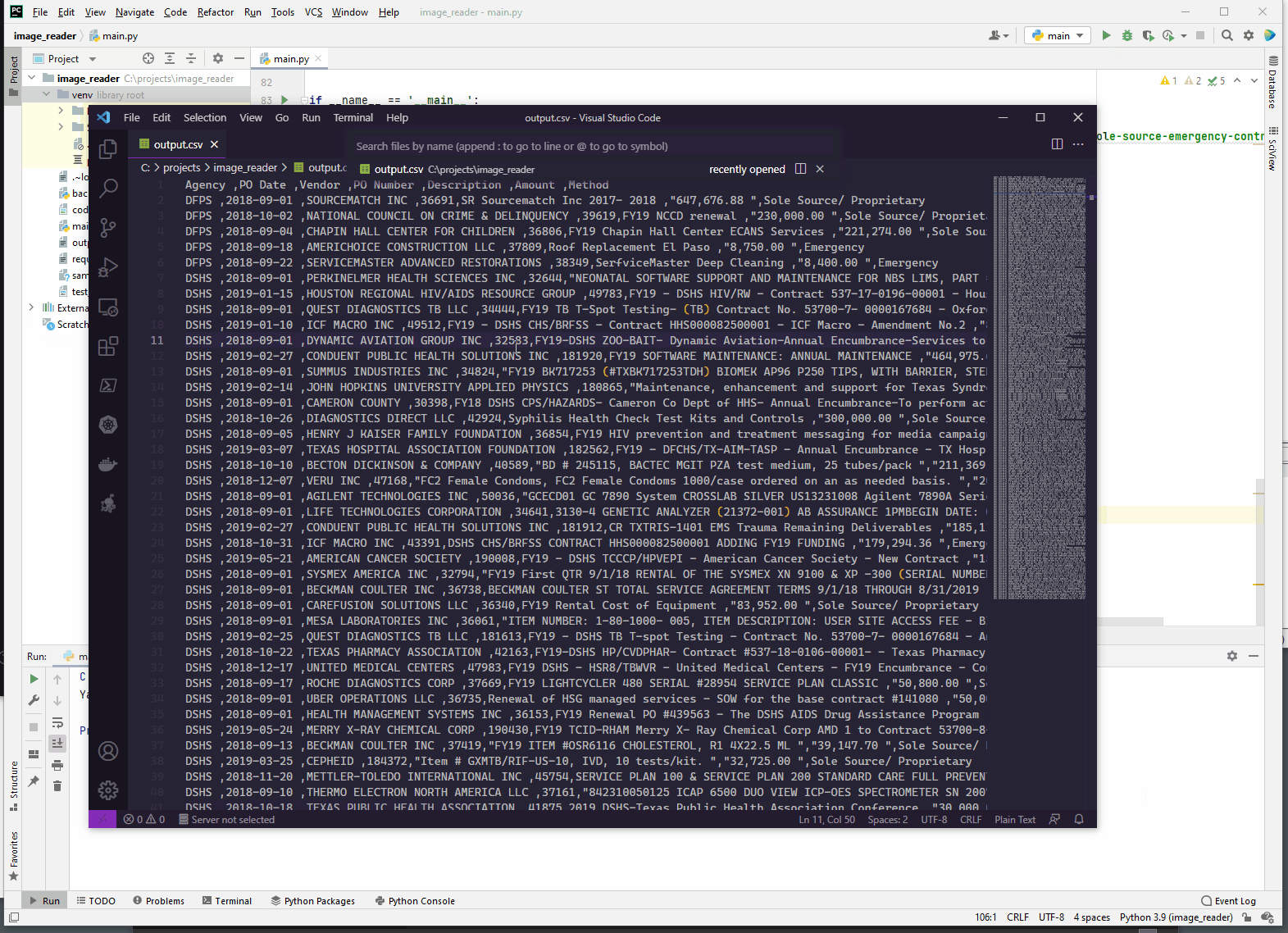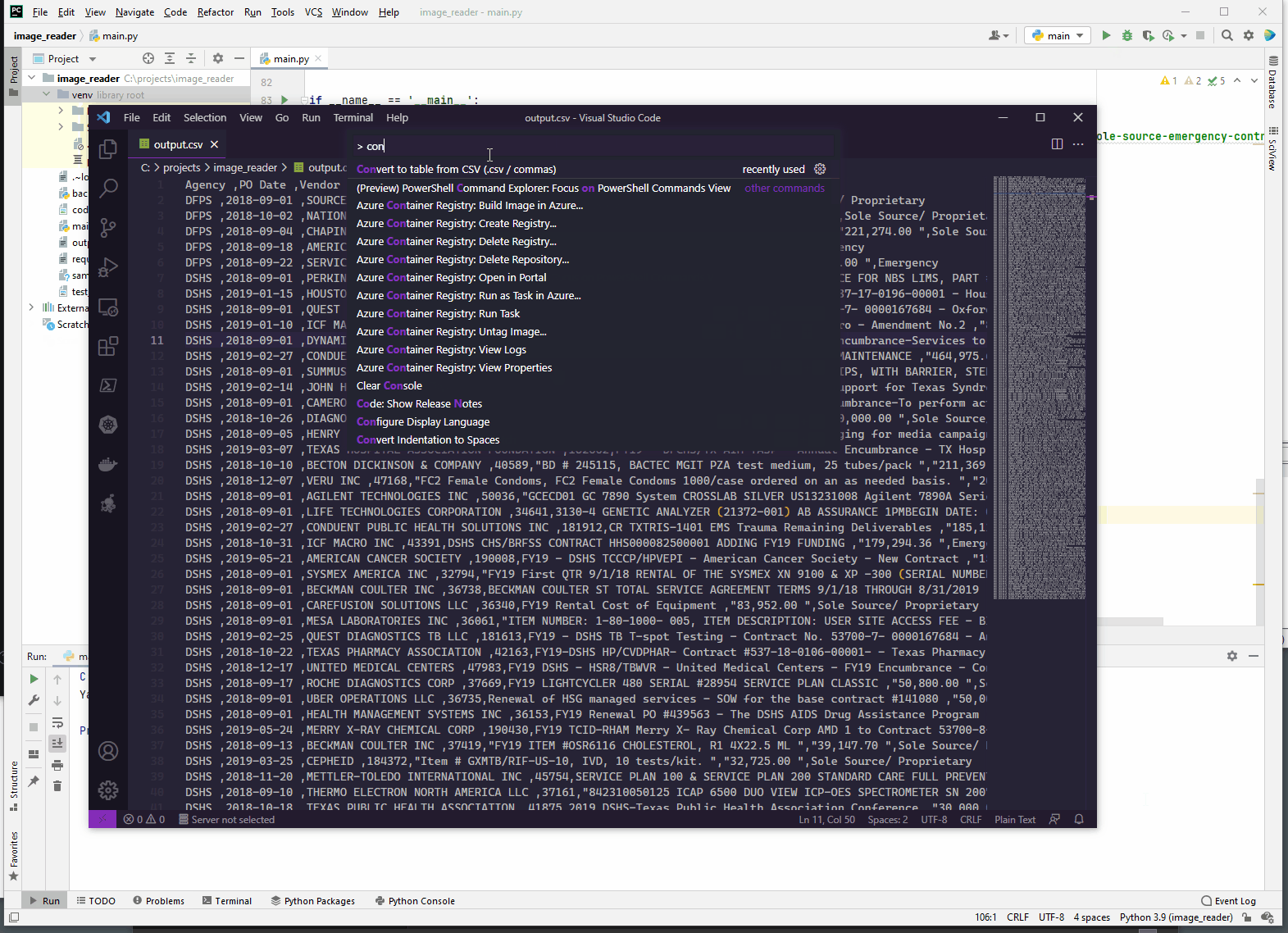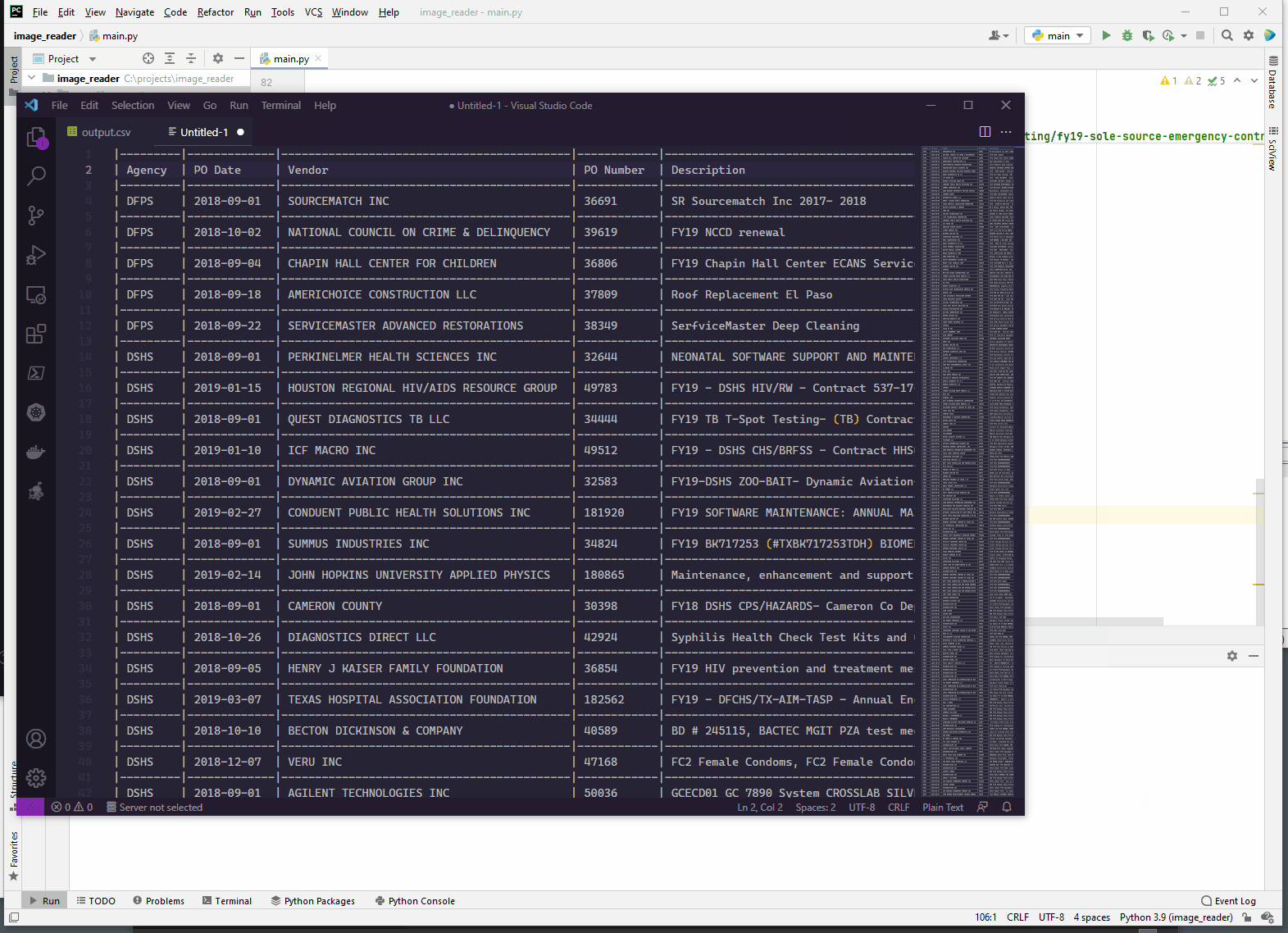
- Export the merged dataframes as csv
import csv
import io
import itertools
import os
import boto3
import pandas as pd
from PIL.Image import Image
from pdf2image import convert_from_bytes
import requests
def get_rows_columns_map(table_result, blocks_map):
rows = {}
for relationship in table_result['Relationships']:
if relationship['Type'] == 'CHILD':
for child_id in relationship['Ids']:
cell = blocks_map[child_id]
if cell['BlockType'] == 'CELL':
row_index = cell['RowIndex']
col_index = cell['ColumnIndex']
if row_index not in rows:
# create new row
rows[row_index] = {}
# get the text value
rows[row_index][col_index] = get_text(cell, blocks_map)
return rows
def get_text(result, blocks_map):
text = ''
if 'Relationships' in result:
for relationship in result['Relationships']:
if relationship['Type'] == 'CHILD':
for child_id in relationship['Ids']:
word = blocks_map[child_id]
if word['BlockType'] == 'WORD':
text += word['Text'] + ' '
if word['BlockType'] == 'SELECTION_ELEMENT':
if word['SelectionStatus'] == 'SELECTED':
text += 'X '
return text
def file_tables_to_df(textract_response):
blocks_map, table_blocks = extract_tables(textract_response)
all_dfs = []
if len(table_blocks) <= 0:
return all_dfs
for index, table_result in enumerate(table_blocks):
data_rows = get_rows_columns_map(table_result, blocks_map)
mem_file = io.StringIO()
writer = csv.DictWriter(mem_file, data_rows[1])
for row_index in data_rows:
row_data = {k: v.encode('ascii', 'ignore').decode().replace('$', '') for k, v in
data_rows[row_index].items()}
writer.writerow(row_data)
mem_file.seek(0)
df = pd.read_csv(mem_file)
df.to_csv(mem_file, index=False)
all_dfs.append(df)
return all_dfs
def extract_tables(textract_response):
blocks = textract_response['Blocks']
blocks_map = {}
table_blocks = []
for block in blocks:
blocks_map[block['Id']] = block
if block['BlockType'] == 'TABLE':
table_blocks.append(block)
return blocks_map, table_blocks
def image_to_byte_array(pil_image: Image):
img_bytes = io.BytesIO()
pil_image.save(img_bytes, format=pil_image.format)
img_bytes = img_bytes.getvalue()
return img_bytes
if __name__ == '__main__':
sample_pdf_url = 'https://www.hhs.texas.gov/sites/default/files/documents/doing-business-with-hhs/contracting/fy19-sole-source-emergency-contracts.pdf'
pdf_response = requests.get(sample_pdf_url)
pdf_file = os.path.join(os.path.curdir, 'sample.pdf')
open(pdf_file, 'wb').write(pdf_response.content)
pdf_file_bytes = open(pdf_file, 'rb').read()
all_csvs = []
client = boto3.client('textract')
for image in convert_from_bytes(pdf_file_bytes,
poppler_path=r'C:\temp\pystuff\poppler\poppler-21.10.0\Library\bin',
fmt='png'):
image_bytes = image_to_byte_array(image)
response = client.analyze_document(Document={'Bytes': image_bytes}, FeatureTypes=['TABLES'])
current_tables = file_tables_to_df(response)
all_csvs.append(current_tables)
merged = pd.concat(list(itertools.chain(*all_csvs)))
output_file = os.path.join(os.path.dirname(pdf_file), 'output.csv')
merged.to_csv(output_file, index=False)
print("Yay!!!")Example run