Language Phenotypes: C#, SQL, Python - Part 5

Doing a count uniques function and the choice of language really shows some deep decisions on the part of the designers of said language. In this case I will show the answers in C# and Python
Given the problem
Return the set of elements in a string with the frequency of the occurrence. The method signature would look like this
public static Dictionary<string, int> CountFrequency(string input)
What needs to happen is that you should loop through the elements of the input string and count the frequency. In the case I split the string by turning it into a CharArray
Quick and dirty implementation is like this
public static Dictionary<string, int> CountFrequency(string input)
{
var results = new Dictionary<string, int>();
foreach (var element in input.ToCharArray())
{
var key = element.ToString();
if (results.ContainsKey(key))
{
results[key] += 1;
continue;
}
results[key] = 1;
}
return results;
}This can definitely be improved, but it works reliably well and is clear in intent for someone to understand. The complete program would look like the following where it checks to match input to expected output. Copy and paste it into dotnetfiddle.net for testing
using System;
using System.Linq;
using System.Collections.Generic;
public class Program
{
public static Dictionary<string, int> CountFrequency(string input)
{
var results = new Dictionary<string, int>();
foreach (var element in input.ToCharArray())
{
var key = element.ToString();
if (results.ContainsKey(key))
{
results[key] += 1;
continue;
}
results[key] = 1;
}
return results;
}
public static void Main()
{
var expected = new Dictionary<string, int>
{
{ "a", 4},
{ "b", 1}
};
var output = CountFrequency("aaaab");
var matches = 0;
foreach (var expectedItem in expected)
{
if (expectedItem.Value == output[expectedItem.Key]){
matches++;
}
}
Console.WriteLine(string.Format("Expected matches {0} actual matches {1}", expected.Keys.Count(), matches));
}
}and you get the following: Expected matches 2 actual matches 2
Cool, but if you put in a unicode type character in the string (🦥) things go bad like so:
var expected = new Dictionary<string, int>
{
{ "a", 4},
{ "b", 1},
{ "🦥", 1}
};
var output = CountFrequency("aaaab🦥");and you get the following:
Run-time exception (line 35): The given key was not present in the dictionary.
Stack Trace:
[System.Collections.Generic.KeyNotFoundException: The given key was not present in the dictionary.]
at System.Collections.Generic.Dictionary`2.get_Item(TKey key)
at Program.Main() :line 35What key is failing? Add this at 35 - Console.WriteLine(expectedItem.Key); and you find it is the emoji unicode sloth 🦥
a
b
🦥
Run-time exception (line 36): The given key was not present in the dictionary.What happened the string got split and iterated on. If you stick a Console.WriteLine up at line 12 like so Console.WriteLine(element); you will see that the sloth gets printed out as a weird key of ? or ?? because the unicode is getting chopped off as strings in C# are 2 byte (16 bit) length but this particular element is a 4 byte unicode (32 bit) character and it confuses and blows up the system. Also this seems to cause an infinite print loop so be careful.
How can we fix this quickly to count our sloth characters? If you are saying characters all have lookup codes 97 = a you would be right and it seems to work but it doesn't match right because the function ToCharArray is giving to characters for sloth 🦥 = 55358 first 2 bytes and 56741 last 2 bytes.
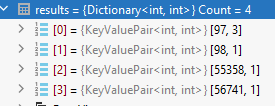
So my expected set doesn't match now
var expected = new Dictionary<int, int>
{
{ Convert.ToInt32("a"[0]), 4},
{ Convert.ToInt32("b"[0]), 1},
{ Convert.ToInt32("🦥"[0]), 1}
};You could go down the path of doing some encoding swaps to put the string into unicode and then read the bytes and so forth. The int codes solution does work with a little adjustment though here.
Blah no thanks I got quick way to do this. Let sql handle data better as it knows the difference between unicode and ansi etc much better.
The plan
- Open SQLite in memory database
- Create a recursive Common Table Expression (CTE) to query the elements of the input string and group by the values
- Send it back into C# code with Dapper
What does that look like
public class Counter
{
public string Element { get; set; }
public int Counts { get; set; }
}
public static Dictionary<string, int> CountFrequency(string input)
{
using var db = new SQLiteConnection("Data Source=:memory:");
return db.Query<Counter>(@"WITH t(pos, element) AS (
SELECT 1, substr(@inputText, 1, 1)
UNION ALL
SELECT pos+1, substr(@inputText, pos+1, 1)
FROM t
WHERE pos < length(@inputText)
)
SELECT element, count(*) as counts
FROM t
GROUP BY element", new { inputText = input })
.ToDictionary(counter => counter.Element, counter => counter.Counts);
}The key is to split each index position with the recursive CTE and then union the results back up into a dataset then map it back to a class and convert to dictionary.
And the final code looks like this
using System;
using System.Linq;
using System.Collections.Generic;
using System.Data.SQLite;
using Dapper;
public class Program
{
public class Counter
{
public string Element { get; set; }
public int Counts { get; set; }
}
public static Dictionary<string, int> CountFrequency(string input)
{
using var db = new SQLiteConnection("Data Source=:memory:");
return db.Query<Counter>(@"WITH t(pos, element) AS (
SELECT 1, substr(@inputText, 1, 1)
UNION ALL
SELECT pos+1, substr(@inputText, pos+1, 1)
FROM t
WHERE pos < length(@inputText)
)
SELECT element, count(*) as counts
FROM t
GROUP BY element", new { inputText = input })
.ToDictionary(counter => counter.Element, counter => counter.Counts);
}
public static void Main()
{
var expected = new Dictionary<string, int>
{
{ "a", 3},
{ "b", 1},
{ "🦥", 1}
};
var output = CountFrequency("aaab🦥");
var matches = expected.Count(expectedItem => expectedItem.Value == output[expectedItem.Key]);
Console.WriteLine($"Expected matches {expected.Keys.Count} actual matches {matches}");
}
}Testing it out you get: Expected matches 3 actual matches 3
Success!!
Python implementation
Well python supports unicode from the start so this whole exercise boils down to the following
input = "aaabc🦥"
expected_output = {"a": 3, "b": 1, "c": 1, "🦥": 1}
print(f"Input and Expected Output are equal: {dict(Counter(input)) == expected_output}")Python wins again and so easily as well (🙇♂️)
Second question
Identify and remove all duplicates from a table with sql. Now this is use a group by and min/max to pick the elements to keep. Using SQLite again start with a table and data like this
drop table if exists Thing;
create table Thing (Id integer primary key AUTOINCREMENT, Name varchar(256));
insert into Thing (Name) values
('Foo'),
('Foo'),
('Bar'),
('Baz'),
('Boo'),
('Boo'),
('Foo');You have
| Id | Name |
|---|---|
| 1 | Foo |
| 2 | Foo |
| 3 | Bar |
| 4 | Baz |
| 5 | Boo |
| 6 | Boo |
| 7 | Foo |
Use a CTE to identify and delete elements like so
WITH dups
AS
(
select MIN(ID) as KeepId
from Thing
GROUP BY Name
)
DELETE
FROM Thing
WHERE Id NOT IN dups;And results are
| Id | Name |
|---|---|
| 1 | Foo |
| 3 | Bar |
| 4 | Baz |
| 5 | Boo |
SQL capabilities coming to the forefront here again. The idea is the closer you can push the operation code to the data the more powerful things you can do. Now you weigh this against flexibility, maintenance, and requirements but yeah.